
Le paysage de l'intelligence artificielle appliquée au génie logiciel a franchi un cap historique au cours du premier trimestre de l'année 2026. L'époque des simples assistants conversationnels capables de générer des bribes de code isolées est désormais révolue, laissant place à des systèmes agentiques autonomes capables de raisonner sur des dépôts de code entiers (repositories), de planifier des migrations complexes et de collaborer en essaims de sous-agents. Cette mutation technologique est portée par une concurrence frontale entre les laboratoires américains, emmenés par Anthropic et OpenAI, et les laboratoires chinois, tels qu'Alibaba avec Qwen 3 et Moonshot AI avec Kimi K2.5. Pour une organisation technique s'appuyant sur l'infrastructure AWS Bedrock, le choix du modèle ne se limite plus à une simple comparaison de précision syntaxique, mais englobe désormais des dimensions de fenêtre de contexte, de protocoles de communication entre agents (MCP) et d'efficacité de coût à l'échelle industrielle.
L'émergence de Claude Opus 4.6 : La suprématie de l'architecte cognitif
Lancé le 5 février 2026, Claude Opus 4.6 représente le sommet actuel de la hiérarchie des modèles d'Anthropic. Conçu pour être le modèle le plus intelligent du marché, il se distingue par une focalisation accrue sur le codage agentique, le raisonnement profond et, surtout, l'autocorrection. Cette itération marque un passage de "l'action" à "l'action soutenue", où le modèle ne se contente pas de répondre à une requête, mais maintient une cohérence opérationnelle sur des périodes prolongées.
Mécanismes de la fenêtre de contexte et lutte contre la dégradation
L'innovation majeure de Claude Opus 4.6 réside dans sa fenêtre de contexte d'un million de jetons (tokens), actuellement en phase bêta pour les niveaux d'utilisation élevés. Ce volume massif permet d'ingérer l'équivalent de 750 000 mots ou plusieurs bibliothèques logicielles entières en une seule session. Plus crucialement, Anthropic semble avoir résolu le problème persistant de la "pourriture du contexte" (context rot), où les performances d'un modèle se dégradent à mesure que la discussion s'allonge. Sur le benchmark MRCR v2, qui teste la capacité de récupération d'informations enfouies dans de vastes documents, Opus 4.6 atteint un score de 76 % avec huit aiguilles cachées dans un million de jetons, là où son prédécesseur Sonnet 4.5 ne parvenait qu'à 18,5 %.
Cette persistance contextuelle permet aux ingénieurs d'effectuer des migrations de code s'étendant sur des millions de lignes comme s'ils travaillaient avec un ingénieur senior ayant une mémoire parfaite de l'architecture globale. Le modèle est capable de tracer des fuites d'abstractions entre plusieurs services backend et de maintenir les décisions de conception cohérentes du début à la fin d'une construction d'application.
Raisonnement adaptatif et contrôle de l'effort
Le passage au mode "Adaptive Thinking" constitue une rupture avec l'approche binaire des modèles de 2025. Claude Opus 4.6 analyse désormais la complexité de chaque requête pour décider dynamiquement du budget de raisonnement à allouer. Le paramètre d'effort associé propose quatre niveaux : bas, moyen, haut (par défaut) et max. En mode effort maximum, le modèle revisite méticuleusement son propre raisonnement avant de produire une réponse, ce qui élimine de nombreuses erreurs subtiles que d'autres modèles manquent, mais au prix d'une latence et d'un coût de jetons accrus. Cette flexibilité permet d'utiliser le même modèle pour des tâches de refactorisation simples (en mode moyen) et pour le débogage critique de systèmes distribués (en mode max).

Qwen 3 : L'efficacité industrielle et l'optimisation monorepo
Le laboratoire Alibaba a positionné Qwen 3 comme une alternative open-weight redoutable, spécifiquement optimisée pour les environnements de production à grande échelle sur AWS Bedrock. Disponible en plusieurs tailles, du modèle dense de 32B au flagship Mixture-of-Experts (MoE) de 480B, la série Qwen 3 mise sur une architecture hybride pour concilier puissance de calcul et économie de ressources.
L'innovation Gated DeltaNet et l'attention linéaire
Le succès technique de Qwen 3, et particulièrement de sa variante Qwen3-Coder-Next, repose sur l'intégration de Gated DeltaNet, un mécanisme d'attention linéaire à complexité O(n). Cette architecture permet de traiter des contextes longs sans subir le ralentissement quadratique typique des modèles Transformers classiques. En pratique, cela signifie que Qwen 3 peut analyser des dépôts de code entiers avec une vitesse d'inférence supérieure, tout en conservant une attention "globale" nécessaire pour comprendre les relations entre fichiers distants.
Le modèle Qwen3-Coder-Next est un exemple frappant de cette efficacité : avec seulement 3 milliards de paramètres activés par jeton, il atteint des performances sur SWE-bench Verified (environ 70 %) comparables à des modèles activant 10 à 20 fois plus de paramètres. Pour une entreprise utilisant Bedrock, cela se traduit par une réduction drastique du coût total de possession (TCO) pour des agents "toujours allumés" qui surveillent les pipelines de CI/CD ou automatisent la maintenance préventive.
Intégration native dans l'écosystème Bedrock
Alibaba a travaillé étroitement avec AWS pour assurer que Qwen 3 soit disponible en tant que service serverless managé. Cette intégration permet aux développeurs d'accéder aux modèles via une API unifiée, bénéficiant de la sécurité de niveau entreprise d'AWS (IAM, VPC, PrivateLink) et de l'autoscaling sans gestion d'infrastructure. Qwen 3 supporte nativement le Model Context Protocol (MCP), ce qui facilite son branchement sur des outils de recherche web, des bases de données et des interpréteurs de code au sein du framework Bedrock AgentCore.
Kimi K2.5 : L'essaim d'agents et l'intelligence visuelle native
Moonshot AI, avec le lancement de Kimi K2.5 en janvier 2026, a introduit une vision radicalement décentralisée de l'assistance au code. Ce modèle Mixture-of-Experts de 1040 milliards de paramètres (dont 32 milliards actifs) est le premier à intégrer nativement la technologie "Agent Swarm".
La technologie Agent Swarm et l'apprentissage PARL
Contrairement aux approches traditionnelles où un agent traite les tâches de manière séquentielle, Kimi K2.5 peut instancier dynamiquement jusqu'à 100 sous-agents spécialisés travaillant en parallèle. Ce système est piloté par un orchestrateur entraîné via le Parallel-Agent Reinforcement Learning (PARL), une méthode qui enseigne au modèle comment décomposer des requêtes complexes en sous-tâches indépendantes.
L'efficacité de l'essaim est mesurée par la métrique des "Étapes Critiques" (Critical Steps), inspirée du calcul parallèle, qui optimise la latence du chemin le plus long plutôt que le nombre total d'étapes. Dans les scénarios de recherche d'informations sur le web ou de génération de code pour des interfaces denses, cette approche réduit le temps d'exécution de 80 % par rapport à un agent unique. Pour un développeur, cela signifie que Kimi peut, en une seule commande, lancer un agent "Chercheur de doc", un agent "Générateur d'API" et un agent "Rédacteur de tests", puis synthétiser leurs travaux respectifs sans intervention humaine.
Le codage par la vision (Coding with Vision)
Kimi K2.5 se distingue également par son entraînement multimodal natif sur 15 billions de jetons mixtes texte-vision. Cette capacité permet des flux de travail révolutionnaires :
- Reconstruction de sites web à partir de vidéos : En analysant l'enregistrement d'une interface, le modèle peut reconstruire la structure CSS/HTML, les animations JavaScript et la logique de navigation
- Débogage visuel autonome : Le modèle peut "regarder" une capture d'écran d'un bug UI, consulter la documentation du framework concerné et itérer sur le code jusqu'à ce que le rendu visuel soit conforme aux attentes.
- Tradition esthétique vers code : Une démonstration notable a montré Kimi K2.5 traduisant l'esthétique du tableau "La Danse" de Matisse en une interface web fonctionnelle, prouvant une compréhension profonde du style, des couleurs et de la mise en page spatiale.
Analyse comparative des performances agentiques
L'évaluation de la performance au début de l'année 2026 s'appuie sur des benchmarks simulant l'activité réelle d'un ingénieur dans un environnement de terminal et de repository complexe.
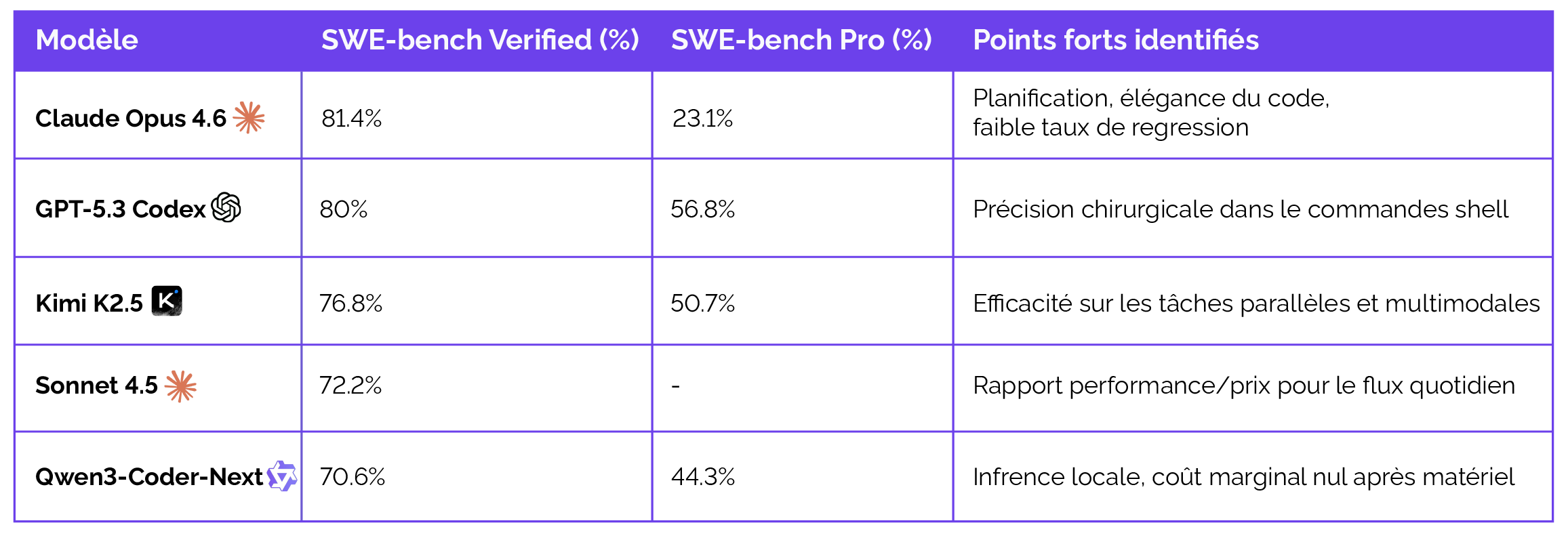
SWE-bench Verified et Pro : La réalité de la production
SWE-bench Verified est devenu le test de référence pour mesurer la capacité d'un modèle à résoudre de véritables issues GitHub dans des repositories de plus de 10 000 lignes. Claude Opus 4.6 y maintient une position de leader avec 81,4 %, bien que l'augmentation par rapport à la version 4.5 soit marginale, soulignant une stabilisation de la précision au profit de la fiabilité architecturale.
Une découverte majeure de 2026 est la chute drastique des scores sur SWE-bench Pro, un jeu de données plus récent et protégé contre la contamination. Les modèles qui affichent plus de 70 % sur la version Verified chutent souvent aux alentours de 23 % sur la version Pro, ce qui démontre que la résolution autonome de problèmes inédits reste le défi ultime pour les IA de pointe.
Terminal-Bench 2.0 : L'interaction avec le système
Terminal-Bench 2.0 évalue la capacité du modèle à naviguer dans un système de fichiers, à utiliser des compilateurs et à interpréter les sorties de logs pour corriger des erreurs système. GPT-5.3 Codex domine actuellement ce segment avec 77,3 %, tandis que Claude Opus 4.6 se maintient à 65,4 %. L'analyse suggère que Claude est plus "prudent" et "réflexif", ce qui peut le ralentir dans des workflows de commandes rapides où Codex agit comme un pur opérateur de terminal.
Qwen 3 et Kimi K2.5 affichent des scores respectifs de 37,5 % et 50,8 %. Bien que inférieurs en valeur absolue, ces modèles sont jugés par les praticiens comme étant "largement suffisants" pour 90 % des tâches d'automatisation DevOps courantes, rendant leur adoption attractive pour des raisons économiques.
Intégration sur AWS Bedrock et Architecture MCP
Pour une organisation standardisant son infrastructure sur AWS, Bedrock offre un cadre de gouvernance et de sécurité que les appels API directs aux laboratoires ne peuvent égaler.
Modèles serverless vs Bedrock Marketplace
L'offre d'assistance au code sur Bedrock se divise en deux catégories d'accès :
- Foundation Models (FM) managés : Claude Opus 4.6 et la suite Qwen 3 sont disponibles en mode serverless avec une facturation au jeton. Ils bénéficient de l'isolation des données AWS, garantissant que le code de l'entreprise n'est jamais utilisé pour l'entraînement des modèles.
- Bedrock Marketplace : Des modèles comme Kimi K2.5 peuvent être déployés via le Marketplace sur des instances gérées par l'utilisateur (Provisioned Throughput). Cela permet un contrôle total sur les politiques d'auto-scaling et le choix des types d'instances.
Le rôle central du Model Context Protocol (MCP)
Le protocole MCP est devenu l'adaptateur universel reliant les modèles aux systèmes de données réels. Sur Bedrock, l'architecture recommandée utilise un client MCP intégré aux agents Bedrock, communiquant avec des serveurs MCP hébergés sur AWS Lambda.
AWS propose désormais des serveurs MCP spécialisés pour :
- AWS IAM : Permet aux agents de requêter les politiques et configurations de sécurité en lecture seule pour l'audit ou le dépannage.
- AWS Cloud Control API : Autorise les agents à créer, mettre à jour ou supprimer des ressources AWS via des instructions en langage naturel.
- S3 & Knowledge Bases : Connecte les modèles aux dépôts de documentation interne pour réduire les hallucinations techniques.
Cette architecture permet de transformer Claude, Qwen ou Kimi d'une intelligence "isolée" en un moteur d'exécution capable d'interagir directement avec le cloud de l'entreprise.
Showdown des outils d'orchestration : Claude Code vs AWS Kiro
Le choix du modèle ne peut être dissocié de l'outil qui l'orchestre. Deux philosophies s'affrontent au début de 2026 : la puissance brute contre la discipline architecturale.
Claude Code : L'autonomie radicale
Claude Code est conçu comme une "enveloppe extrêmement mince" autour de la puissance brute de Claude Opus 4.6. Il fonctionne directement dans le terminal, lit les fichiers, exécute des commandes shell et gère les flux Git de manière autonome jusqu'à ce que la tâche soit accomplie. C'est l'outil de prédilection des développeurs seniors qui souhaitent déléguer des pans entiers de développement et font confiance au modèle pour gérer la complexité sans supervision constante.
Cependant, Claude Code peut être coûteux en consommation de jetons, surtout lors de sessions prolongées sur de gros dépôts, car il a tendance à être verbeux dans son processus de raisonnement interne.
AWS Kiro : Le développement piloté par les spécifications
AWS Kiro adopte une approche radicalement opposée : il impose un workflow structuré "Requirements → Design → Tasks". Lorsqu'un développeur demande une fonctionnalité, Kiro génère d'abord trois documents Markdown que l'humain doit valider :
- requirements.md : Histoires d'utilisateurs et critères d'acceptation.
- design.md : Architecture technique et définitions d'interfaces.
- tasks.md : Liste des étapes d'implémentation traçables.
Cette approche, scientifiquement étayée par des recherches de 2025 montrant qu'une séparation claire entre conception et implémentation réduit le taux d'hallucination de 37 %, agit comme une "étoile polaire" empêchant l'IA de se perdre dans des détails d'implémentation erronés.

Analyse économique et efficacité opérationnelle
Le coût d'exploitation (TCO) d'une IA d'assistance est devenu une préoccupation centrale pour les directeurs techniques en 2026. Le passage à des modèles Mixture-of-Experts a transformé la courbe de prix.
Coût par jeton et économies d'échelle
Anthropic maintient une tarification premium pour Opus 4.6, justifiée par ses capacités de raisonnement exceptionnelles. Cependant, l'apparition de Qwen 3 Coder sur Bedrock a introduit une pression déflationniste massive.
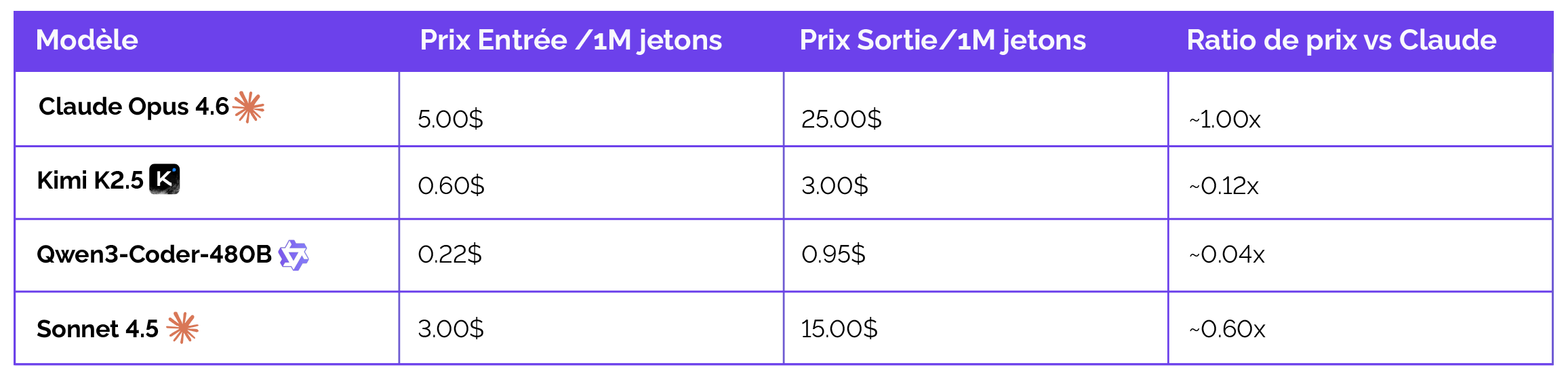
L'écart de prix de 83 fois entre Qwen3-Coder et Claude Opus n'est pas seulement un chiffre ; c'est un changement de paradigme opérationnel. Pour des tâches de fond telles que la génération de documentation technique ou la migration automatique de tests vers de nouveaux frameworks, le coût de Claude peut devenir prohibitif sur des dépôts de plusieurs centaines de milliers de fichiers. À l'inverse, Qwen 3 permet de "prototyper librement" sans craindre une explosion de la facture cloud.
Performance réelle vs "Benchmaxxing"
Une critique récurrente sur les forums de développeurs au début de 2026 est le phénomène de "benchmaxxing", où les modèles chinois sont soupçonnés d'être excessivement optimisés pour briller sur les benchmarks publics au détriment de l'utilité réelle.
Les retours d'expérience indiquent que si Kimi K2.5 et Qwen 3 sont capables de battre Claude sur le papier, ils présentent des lacunes en production :
- Fiabilité "One-shot" : Claude Opus 4.6 réussit souvent des tâches complexes dès le premier essai, là où Qwen 3 demande souvent une ou deux itérations supplémentaires pour corriger des erreurs mineures de syntaxe ou des importations manquantes.
- Latence de réflexion : Kimi K2.5, en raison de son immense pool de paramètres, peut être "péniblement lent", prenant parfois 20 minutes pour générer une application que Claude termine en 3 minutes.
- Cohérence multi-tours : Dans des conversations s'étalant sur plusieurs heures, Qwen 3 "perd parfois le fil" de l'architecture globale, tandis que le système de compaction de Claude maintient une intégrité conceptuelle supérieure.
Les enjeux de souveraineté et de confidentialité des données
L'origine géographique des modèles soulève des questions de conformité réglementaire majeures.
La contrainte chinoise et les solutions AWS
Pour de nombreuses entreprises occidentales, l'envoi de code propriétaire vers des points de terminaison situés en Chine est une interdiction stricte pour des raisons de conformité SOC 2 ou HIPAA. Bedrock résout ce problème en hébergeant les poids des modèles Qwen et Kimi sur des serveurs AWS en Europe ou aux États-Unis, garantissant que les données ne quittent jamais le périmètre de sécurité de l'infrastructure d'Amazon.
L'alternative locale avec Qwen3-Coder-Next
Pour les projets nécessitant une confidentialité absolue ou une utilisation hors ligne, Qwen3-Coder-Next représente une avancée majeure. Grâce à son architecture MoE ultra-légère (3B actifs), ce modèle peut être exécuté localement sur un MacBook Pro ou une station de travail équipée d'une seule RTX 4090 avec une vitesse de 30-40 jetons par seconde. Cette "souveraineté locale" permet aux développeurs de travailler sur des secrets industriels ou des clés API sensibles sans qu'aucun jeton ne quitte leur machine physique.
Synthèse technique et recommandations stratégiques
L'analyse de l'état de l'art au 8 février 2026 montre que le marché est désormais scindé en deux catégories : les modèles "Architectes" et les modèles "Ouvriers de masse".
Claude Opus 4.6 demeure le choix incontesté pour les tâches critiques nécessitant une précision architecturale absolue et une gestion de contexte géante. Sa capacité à livrer un code "prêt pour la production" dès le premier jet minimise le coût caché de la revue de code par les humains.
Qwen 3 et Kimi K2.5 ne sont pas des "illusions" ; ils apportent des capacités uniques que Claude ne possède pas encore, notamment l'orchestration massive en essaim (Kimi) et l'efficacité linéaire pour les repositories géants (Qwen).
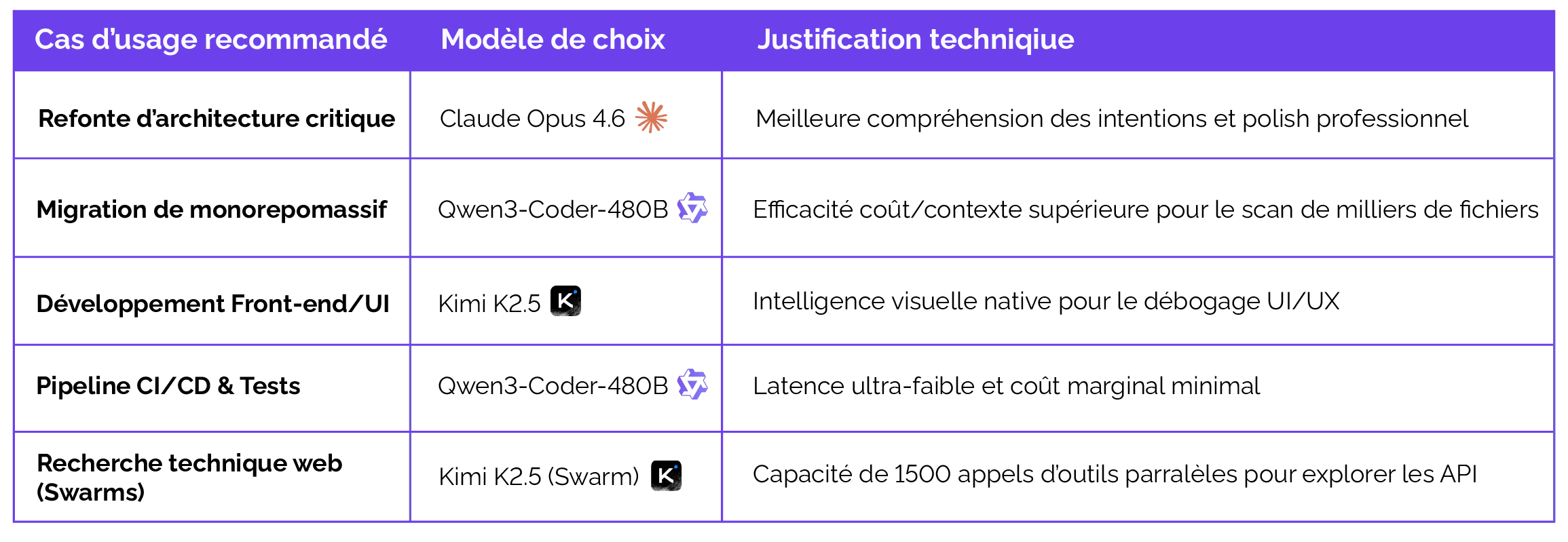
Pour le CTO d'une organisation technologique moderne, la stratégie gagnante en 2026 consiste en une approche multi-modèle orchestrée sur AWS Bedrock. Utiliser Claude Opus 4.6 via Claude Code ou AWS Kiro pour la phase de conception et les revues de code critiques, tout en déléguant l'implémentation de routine, la documentation et les tests unitaires à des modèles comme Qwen 3 ou Kimi K2.5, permet de maximiser la vélocité tout en contrôlant les coûts. L'intégration de ces outils via le protocole MCP assure que l'IA n'est plus seulement un assistant d'écriture, mais un membre à part entière de l'équipe d'ingénierie, capable d'agir sur l'infrastructure et de maintenir la mémoire à long terme du projet.
En définitive, le doute sur les capacités de Qwen et Kimi n'est plus justifié au regard des benchmarks de 2026. S'ils ne remplacent pas encore la "finesse cognitive" de Claude, ils dominent les segments de l'efficacité de masse et de l'intelligence visuelle, forçant une réévaluation complète de la manière dont les budgets d'IA sont alloués dans les entreprises de logiciel.